
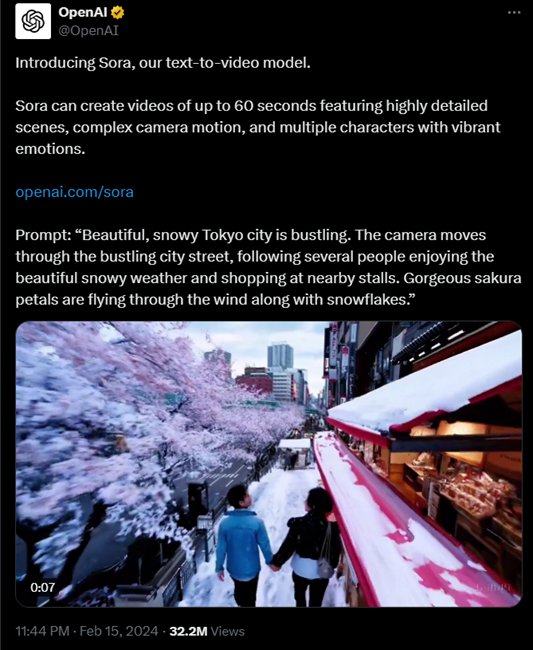
OpenAI has unveiled its latest AI model, Sora, a text-to-video model designed to create videos up to a minute-long, maintaining high visual quality while adhering to user prompts.
According to OpenAI, Sora can generate intricate scenes featuring multiple characters, precise motion, and detailed backgrounds. The model not only comprehends user prompts but also interprets them in the context of the physical world.
Capabilities and Limitations
Sora boasts a profound understanding of language, enabling it to interpret prompts accurately and generate expressive characters with vibrant emotions.
It can craft multiple shots within a single video, ensuring continuity in characters and visual style.
However, OpenAI acknowledges certain weaknesses in the model, such as challenges in simulating complex physics accurately and understanding cause-and-effect relationships.
Spatial details and temporal events may also pose difficulties for Sora, leading to occasional inaccuracies in generated videos.
Safety Measures
Prior to making Sora available in OpenAI products, the company emphasizes implementing rigorous safety measures.
This includes collaborating with domain experts to test the model adversarially and developing tools to detect misleading content.
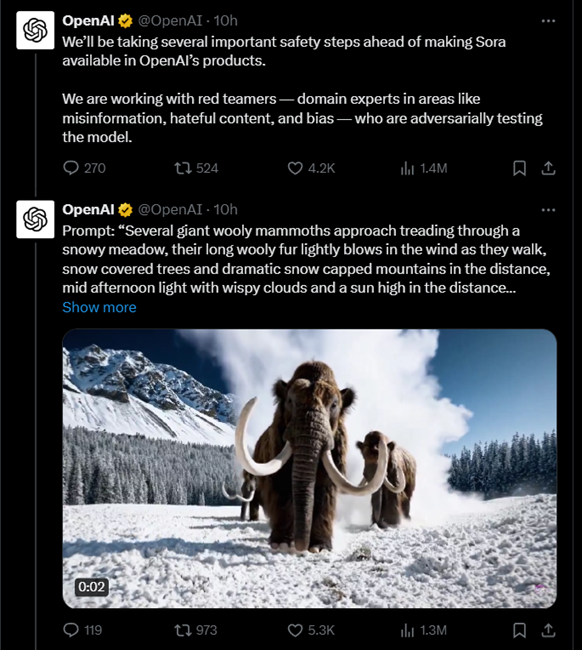
OpenAI also plans to incorporate metadata standards like C2PA and leverage existing safety techniques from previous models. Additionally, they are engaging with various stakeholders globally to understand concerns and identify positive applications for the technology.
Research Techniques and Insights
Sora operates on a diffusion model, gradually transforming noise into coherent video frames. Leveraging transformer architecture, similar to GPT models, Sora demonstrates superior scaling performance.
The model represents videos and images as collections of data patches, enabling training on diverse visual data. Building on past research in DALL·E and GPT models, Sora incorporates recaptioning techniques to faithfully follow user instructions and animate still images or extend existing videos.
Researchers’ Perspectives
Researchers like Bill Peebles highlight Sora’s emergent grasp of cinematic grammar, enabling it to create compelling narratives autonomously. Despite its impressive capabilities, OpenAI remains cautious about potential misuse, particularly in generating deepfakes and misinformation.
Aditya Ramesh, lead researcher and head of the DALL·E team, emphasizes the need for societal understanding and adaptation from social media platforms to mitigate the spread of misinformation.
Additionally, OpenAI addresses concerns regarding copyright infringement by ensuring the use of licensed or publicly available training data.
Availability
OpenAI is making Sora available to red teamers for risk assessment and seeking feedback from visual artists, designers, and filmmakers.
By sharing research progress early, OpenAI aims to engage with external stakeholders and provide insight into upcoming AI capabilities.
You can check out the AI Model at openai.com/sora